鉴于国外开发者已经反馈头条爬虫不遵守 robots.txt 协议 , 因此我们在屏蔽该爬虫时不能只添加robots.txt封禁。最佳做法包括在服务器上直接识别头条爬虫名称然后进行封禁,同时也可以在服务器上封禁头条爬虫的服务器等。有条件的网站建议同时部署所有封禁策略防止部分策略不起作用或有漏网之鱼等等,具体几种封禁策略如下所述:
一、在robots.txt协议中封禁头条爬虫(不一定有用) User-agent: BytespiderDisallow: /
二、在服务器上或者CDN节点上屏蔽头条爬虫IP段:(推荐) 110.249.202.0/24 110.249.201.0/24 111.225.149.0/24 111.225.148.0/24
三、Nginx服务器可参考此地址封禁头条爬虫UA:(推荐)l
四、使用宝塔面板的用户亦可直接在宝塔面板的UA黑名单中屏蔽以下关键词 Bytespider
相关报道:
此前有消息指出字节跳动旗下的今日头条正在开发搜索引擎,目前头条搜索网页手机版已经可以访问和进行搜索。虽然字节跳动官方尚未宣布今日头条通用搜索正式上线推出,不过头条搜索派出的爬虫已经让很多网站痛苦不堪。因为头条搜索使用的爬虫毫无节制的抓爬网站耗费网站的服务器和带宽资源,部分配置较低的网站已经直接瘫痪。
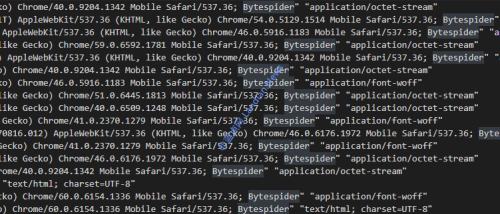
抓爬堪比小型DDoS攻击:
蓝点网在帮朋友网站处理访问异常时便以为是遭遇攻击 , 但排查日志发现名为 ByteSpider 的爬虫才是罪魁祸首。这个爬虫程序便是字节跳动旗下今日头条搜索的,其抓爬频率每秒几十次甚至高达数百次严重影响网站正常访问。正常情况下搜索引擎爬虫会根据网站实际访问性能来进行抓取,即动态调整抓爬频率不会导致网站出现异常情况。显然头条搜索不知道是了快速抓取全网内容还是存在技术问题,爬虫程序直接毫无节制的疯狂抓爬无视网站性能。

3 comments
爬就爬吧, 关键他只爬不收录
头条蜘蛛可以吗?
这就是说的头条蜘蛛啊